


Formation recommandée
250+ Exercices pour Apprendre Python
Apprenez Python efficacement avec plus de 250 exercices pratiques progressifs.
Vous essayez de récupérer le texte d’une image en OCR mais le texte est difficile à lire ? Quelles sont les différentes options pour reconnaître du texte avec Tesseract ?
Tesseract est un logiciel de Reconnaissance Optique de Caractères OCR qui permet de lire du texte à partir d’une image ou d’un document. Il s’utilise en ligne de commande ou dans du code comme en Python avec PyTesseract. Tesseract est personnalisable et supporte plus de 100 langues dont le français.
D’ailleurs si vous voulez en apprendre plus sur PyTesseract, j’ai fait une vidéo pour vous expliquer la reconnaissance optique de caractères.
Découvrons comment lire correctement vos images avec Tesseract !
Comment installer Tesseract ?
Vous pouvez trouver toutes les options d’installation sur la documentation officielle de Tesseract.
Voici un résumé de l’essentiel en français, que vous soyez sur Windows, Linux ou macOS pour installer Tesseract.
Comment installer Tesseract sur Windows ?
Pour installer Tesseract sur Windows, il faut télécharger le fichier executable que vous trouverez sur le GitHub de UB Mannheim (installateurs .exe 64 ou 32 bits).
Lancer l’installateur :
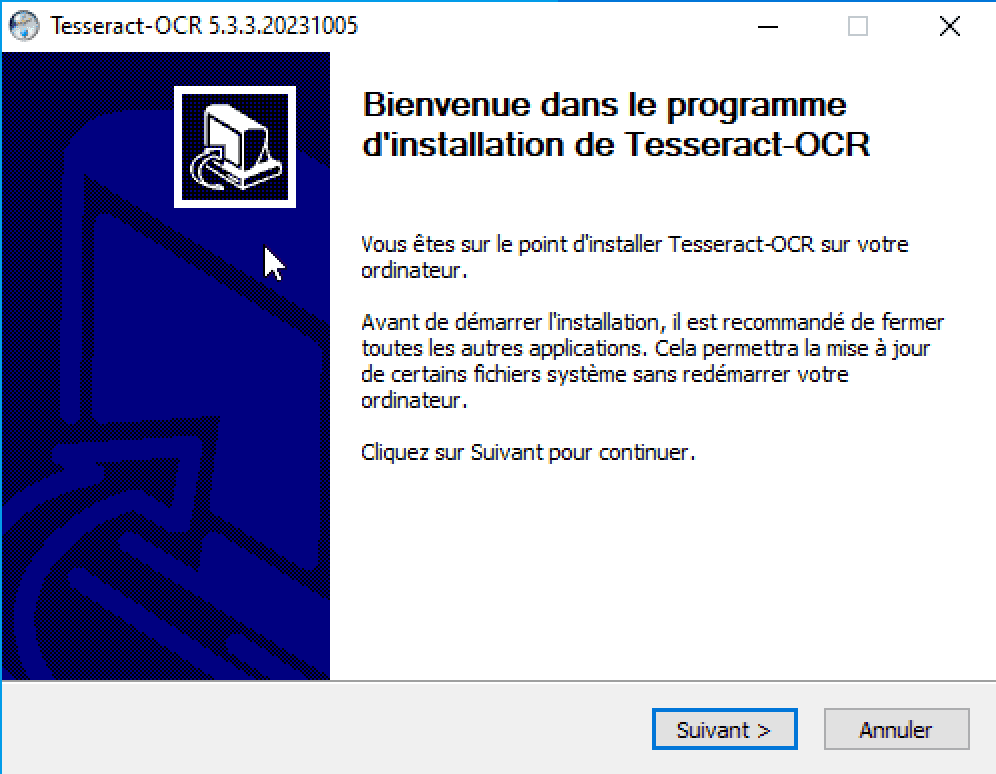
Acceptez la license :
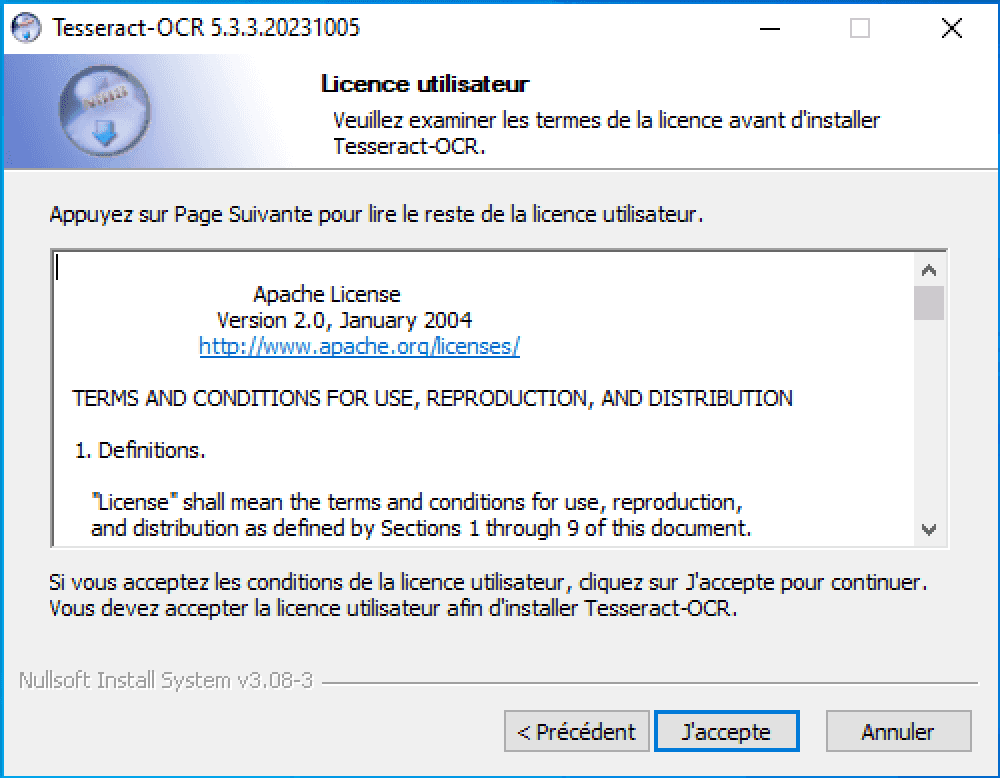
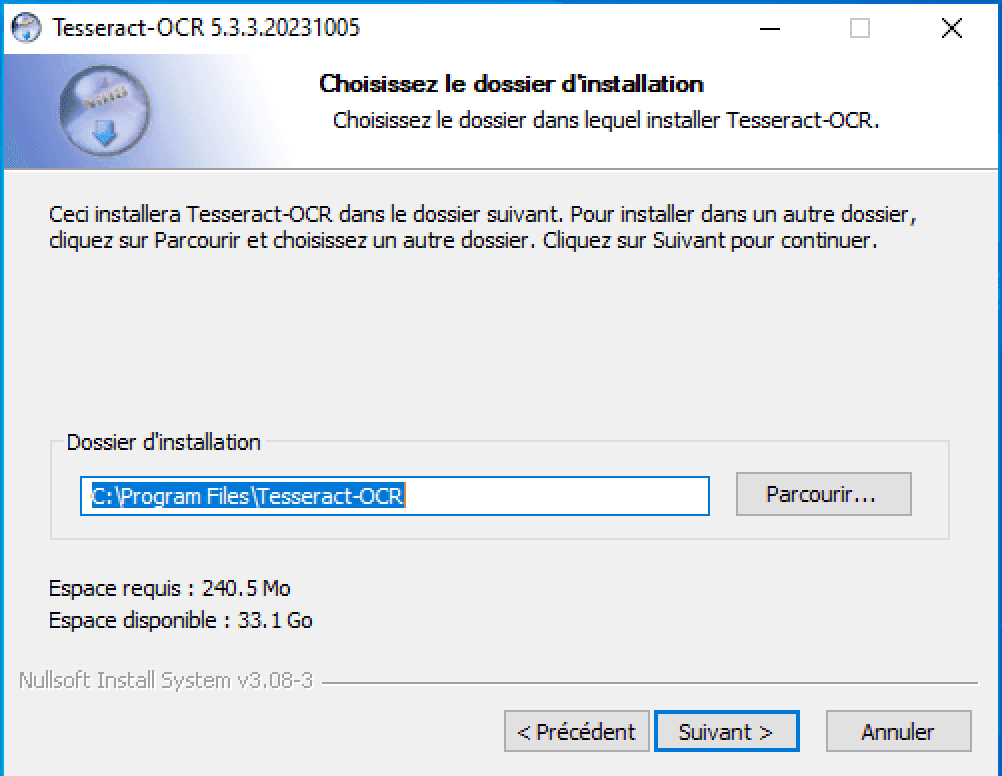
Choisissez le chemin d’installation (copiez le dans le presse-papier, on va en avoir besoin juste après) :
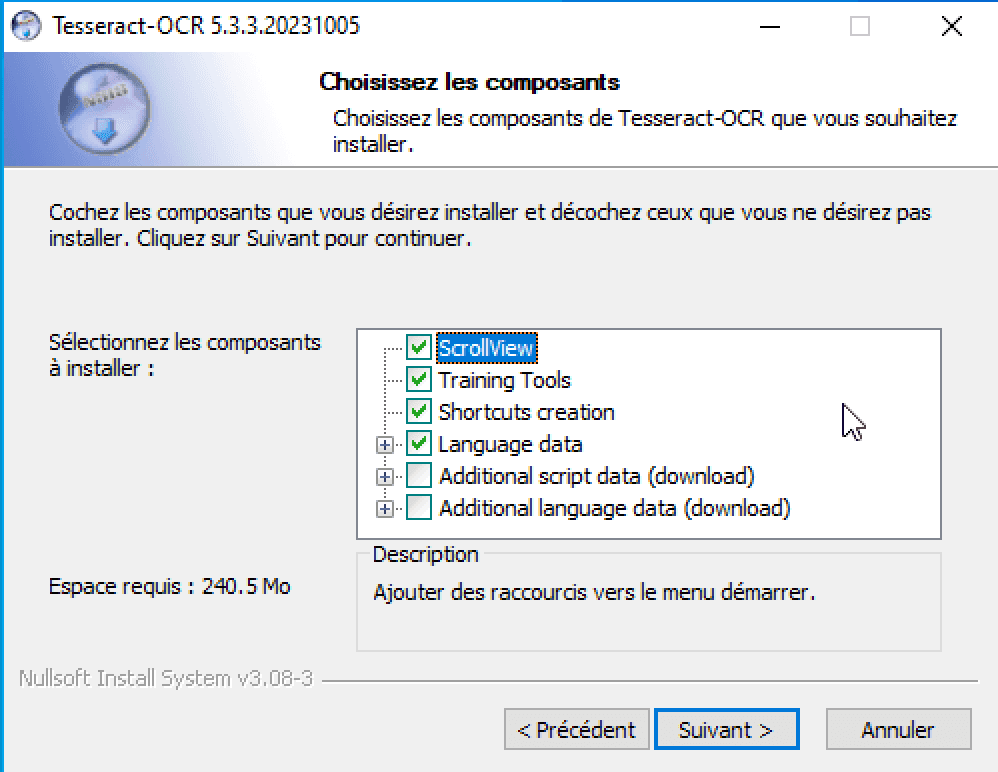
Ajoutez les fichiers de langues si vous voulez lire du texte en français (additional language data) :
Suivant :
Suivant :
Suivant :
Fermer :
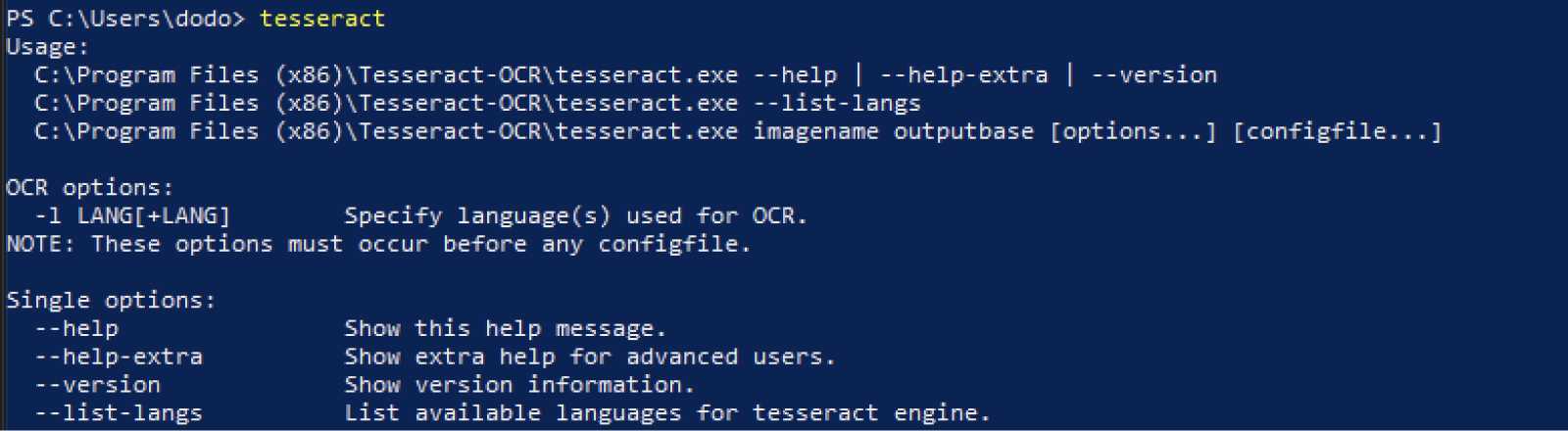
Maintenant si vous lancer tesseract dans un terminal, vous aurez sûrement cette erreur.

C’est parce qu’une fois Tesseract d’installé sur votre machine, vous devrez l’ajouter à vos variables d’environnement.
Pour ouvrir vos variables d’environnement, aller dans l’explorateur et tapez “environ”.
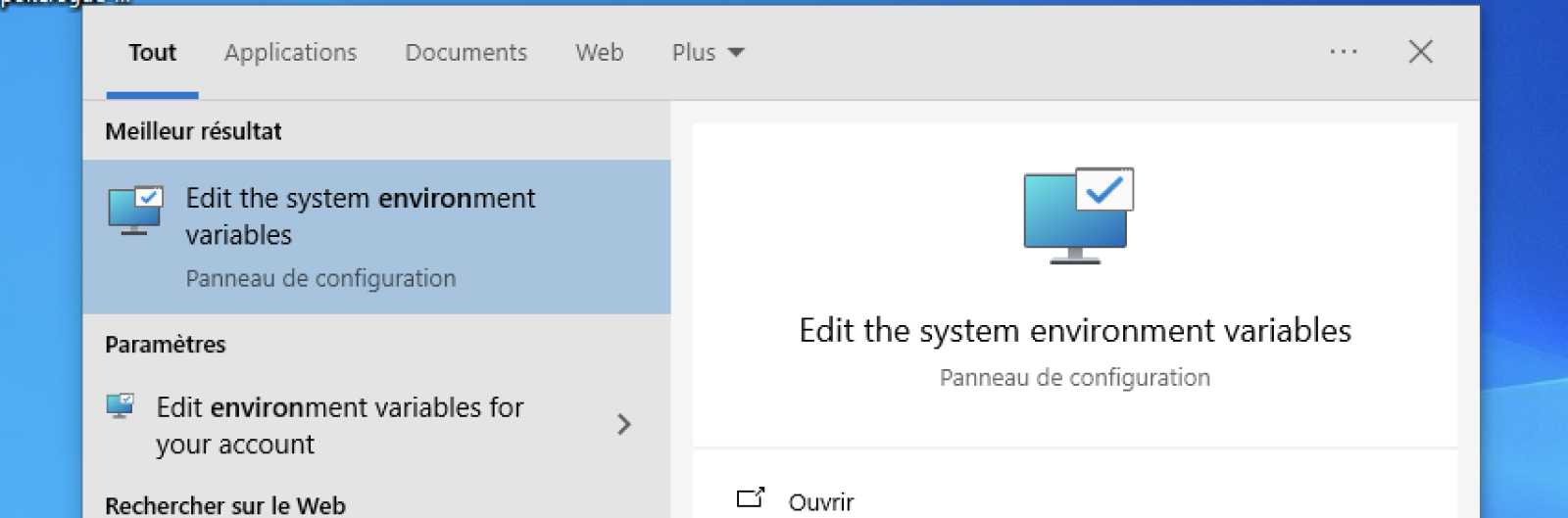
Puis dans Propriétés Système puis dans Avancé et en bas de fenêtre vous trouverez Variables d’Environnements.
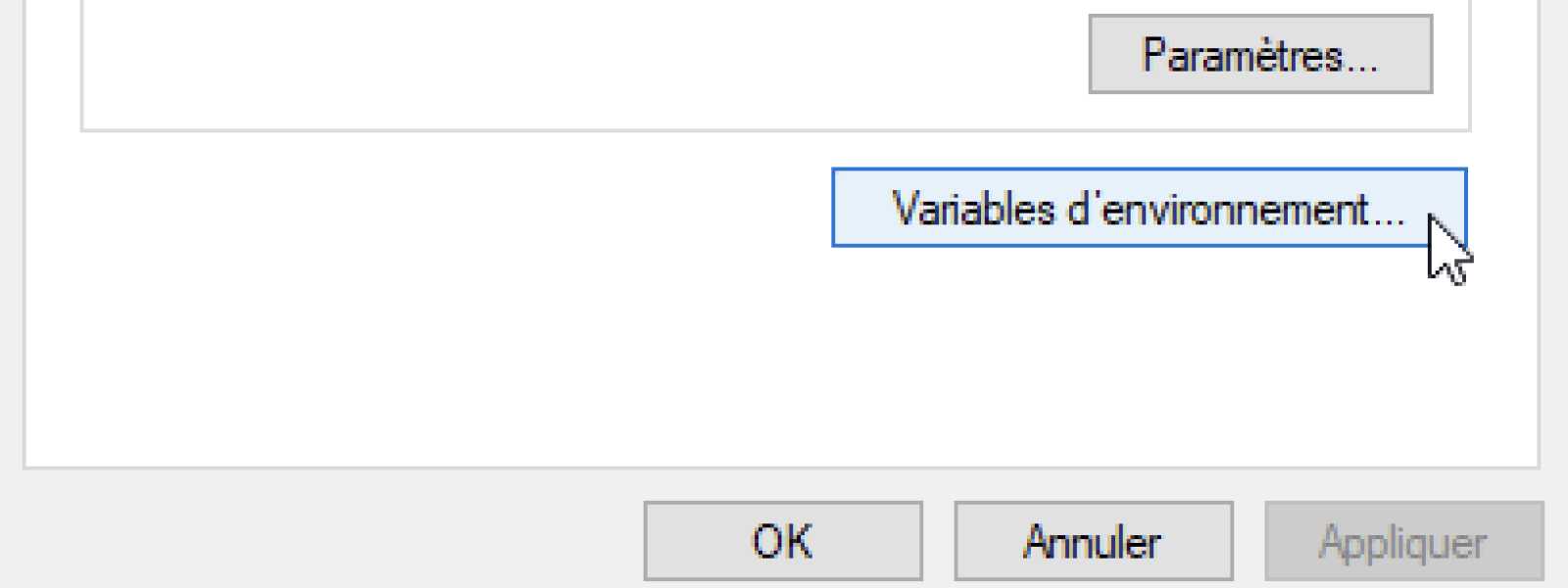
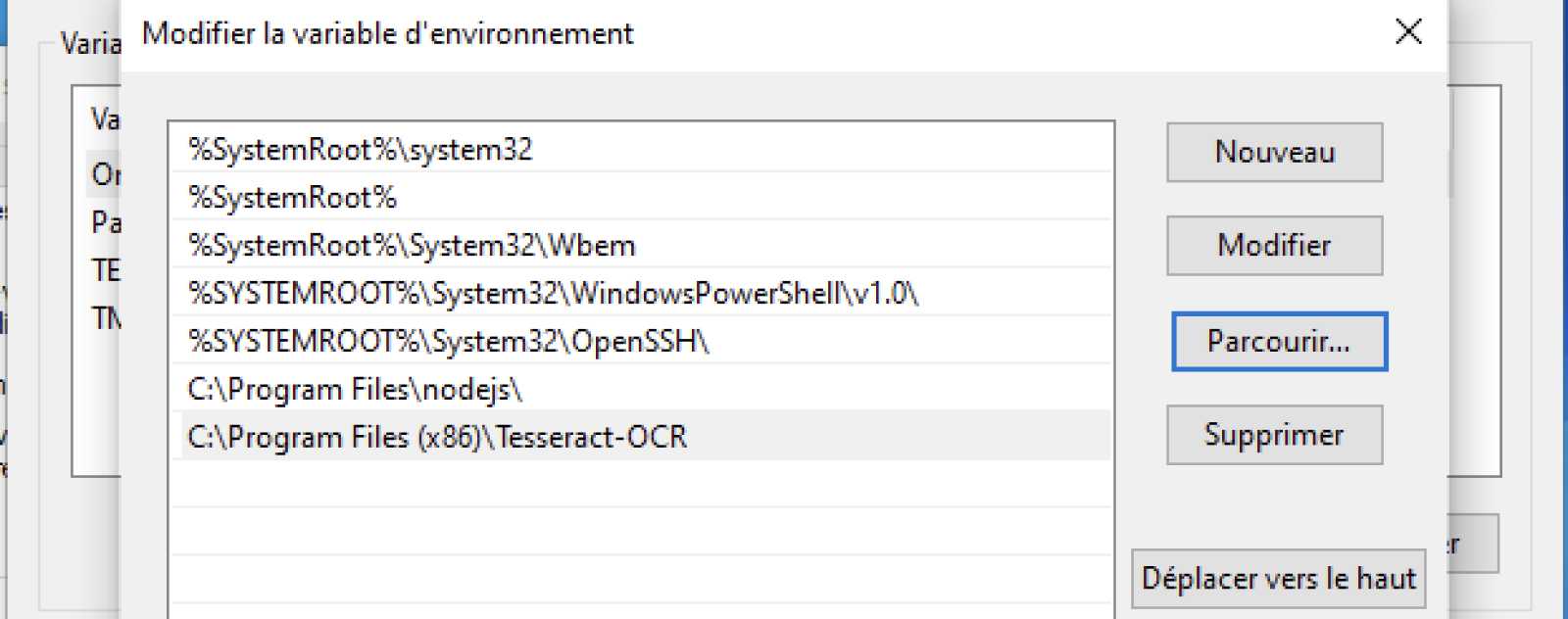
Cliquez dessus et dans la deuxième partie de la nouvelle fenêtre, Variables système, rendez-vous sur la ligne Path puis appuyez sur Modifier.
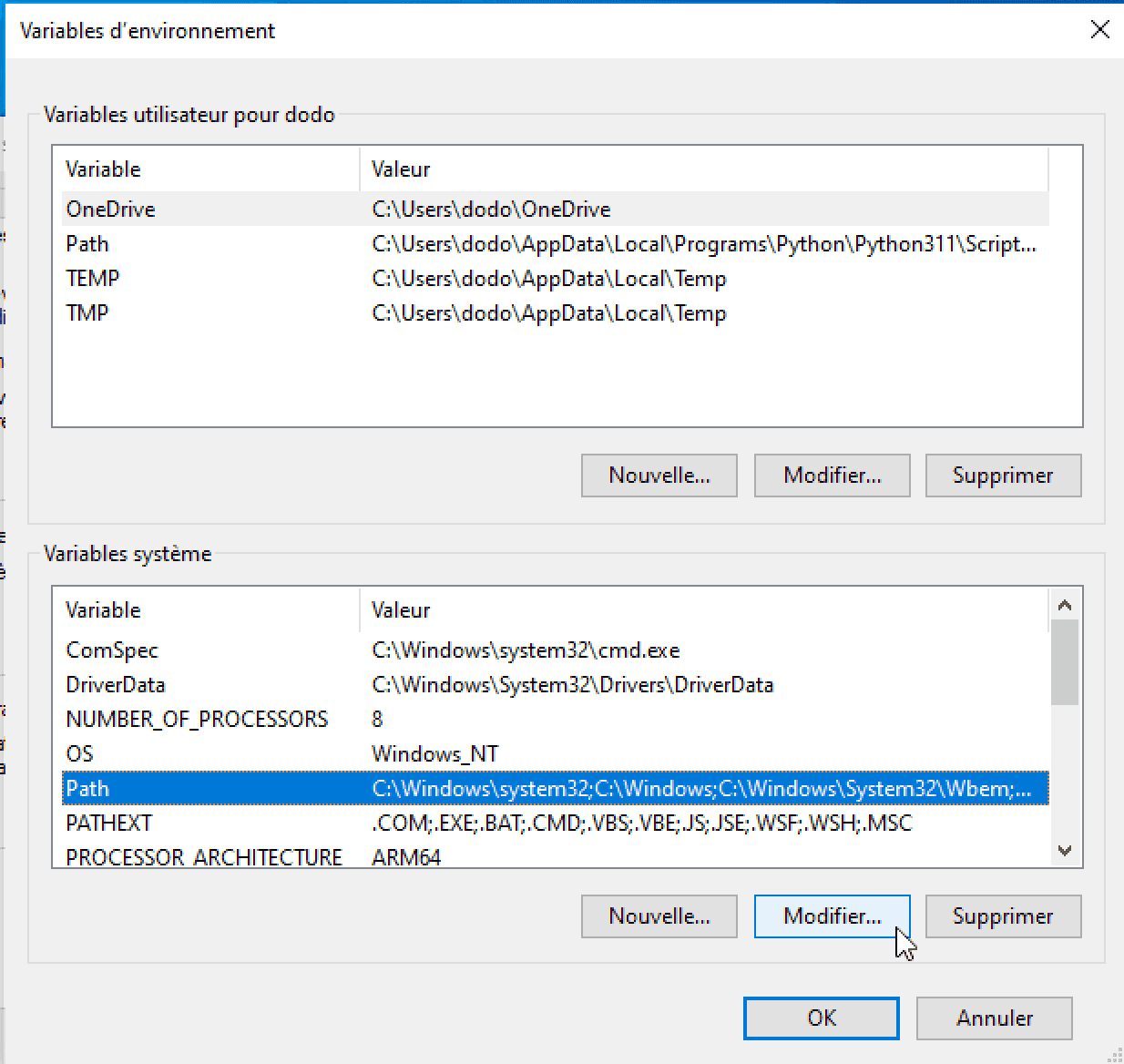
Ensuite faites Parcourir …
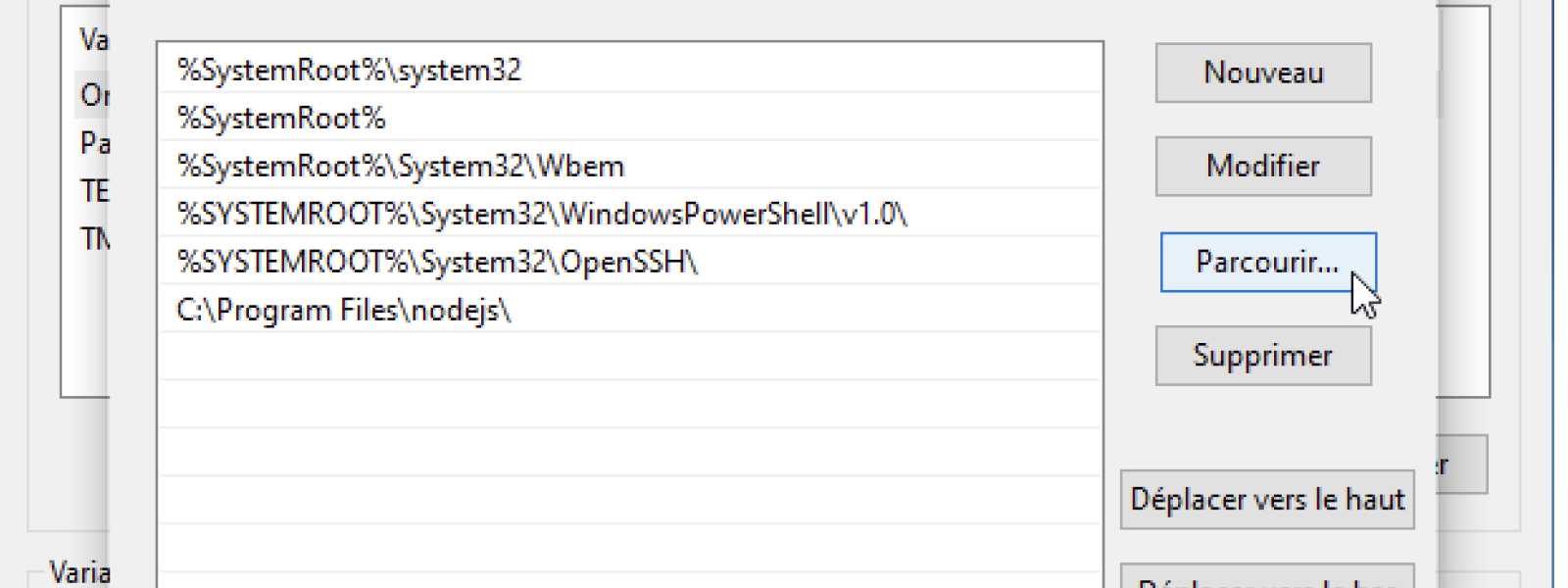
… et allez chercher le dossier de votre installation Tesseract-OCR (sûrement dans C:\Program Files\Tesseract-OCR).
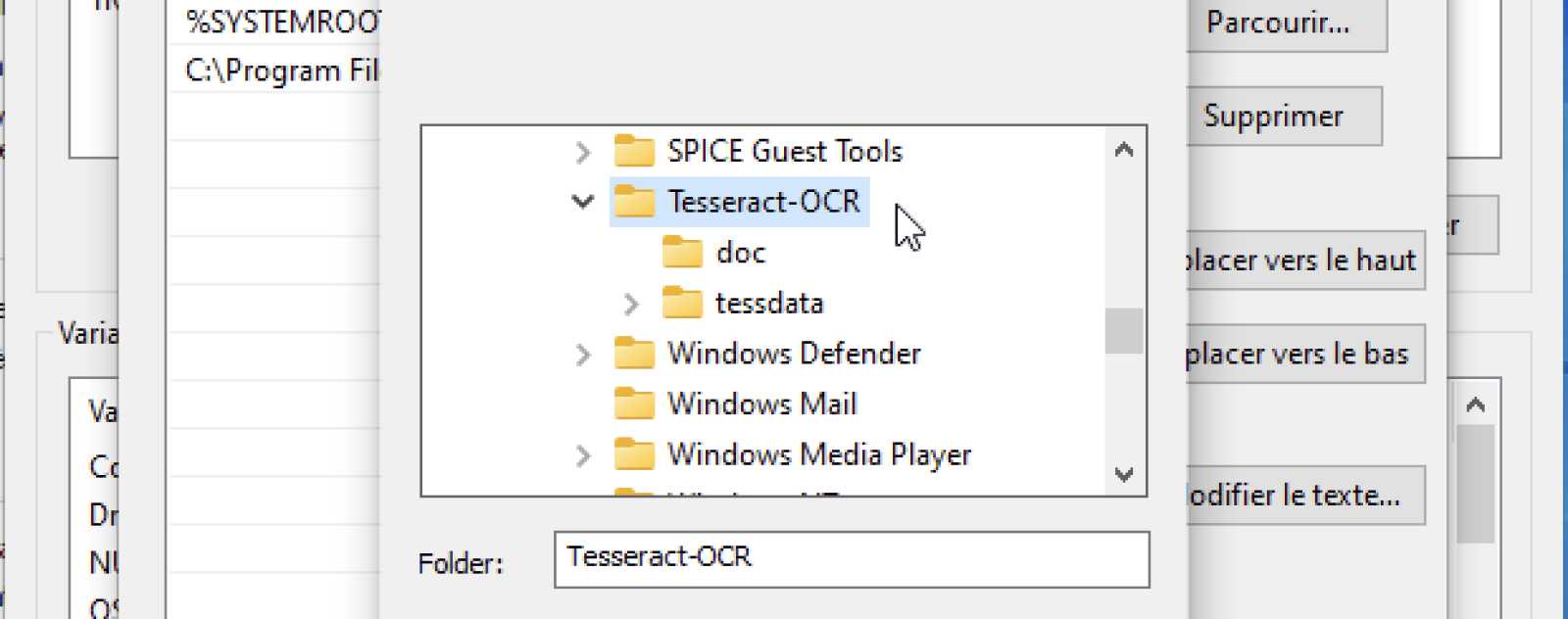
Et vous devriez avoir le chemin listé dans vos variables d’environnement Path.
Si tout s’est bien passé, vous pouvez maintenant utiliser Tesseract en ligne de commande 🎉.
Comment installer Tesseract sur macOS ?
Sur Mac, vous pouvez installer Tesseract avec Homebrew ou MacPorts:
Avec Homebrew :
brew install tesseractEt si vous voulez faire de l’OCR sur des images en différentes langues, vous pouvez télécharger les packs de langues avec :
brew install tesseract --all-languagesAvec MacPorts :
sudo port install TesseractEt pour installer une langue en spécifique, comme le français, vous pouvez faire :
sudo port install tesseract-fraComment installer Tesseract sur Linux ?
Pour installer Tesseract sur Ubuntu, on peut simplement utiliser apt.
sudo apt install tesseract-ocr
sudo apt install libtesseract-devEt si apt ne trouve pas le package, ajoutez deb http://archive.ubuntu.com/ubuntu bionic universe en fin de fichier /etc/apt/sources.list :
sudo vi /etc/apt/sources.list
deb http://archive.ubuntu.com/ubuntu bionic universeComment utiliser Tesseract ?
Pour utiliser Tesseract, on tape tesseract suivi du chemin vers une image et éventuellement des options de lecture :
tesseract mon_image.jpg
tesseract mon_image.png
tesseract mon_document.pdf
tesseract mon_image.jpg -l fra
tesseract mon_image.jpg --oem 2
tesseract mon_image.jpg --psm 2
tesseract mon_image.jpg -l fra --oem 1 --psm 8Comment lire du texte en français avec Tesseract ?
Pour aider Tesseract à reconnaître les mots en français, vous pouvez télécharger un fichier de langue sur le GitHub de Tesseract.
Voici le lien direct vers le fichier pour le français : https://github.com/tesseract-ocr/tessdata/blob/main/fra.traineddata
Ensuite, vous pourrez utiliser l’option langue avec le flag -l suivi de fra pour le français.
Ce qui donne :
tesseract <chemin_vers_l_image> -l fraQuelles sont les options de lecture avec Tesseract ?
Tesseract prend différentes option dans sa ligne de commande en lui passant des arguments. Il est par exemple possible de définir le moteur OCR avec —oem, le mode de segmentation avec —psm, la langue avec -l ou encore le nombre de pixels distincts avec —dpi suivi des valeurs numériques voulues.
Toutes ces options fonctionnent aussi avec les bibliothèques basées sur Tesseract comme PyTesseract.
On peut découvrir tout ça en explorant l’aide de tesseract avec la commande tesseract --help-extra.
Tesseract dispose de plusieurs options qu’on peut lui passer comme :
--tessdata-dir PATH Spécifier l'emplacement du chemin tessdata.
--user-words PATH Spécifier l'emplacement du fichier des mots utilisateurs.
--user-patterns PATH Spécifier l'emplacement du fichier des modèles utilisateurs.
--dpi VALUE Spécifier le DPI de l'image d'entrée.
--loglevel LEVEL Spécifier le niveau de journalisation. LEVEL peut être
ALL, TRACE, DEBUG, INFO, WARN, ERROR, FATAL ou OFF.
-l LANG[+LANG] Spécifier la ou les langues utilisées pour l'OCR.
-c VAR=VALUE Définir la valeur des variables de configuration. (Plusieurs arguments -c sont autorisés.)
--psm NUM Spécifier le mode de segmentation de page
--oem NUM Spécifier le mode du moteur OCR
REMARQUE : Ces options doivent apparaître avant tout fichier de configuration.Comment changer le mode de segmentation de page avec Tesseract ?
Et aussi d’un flag de segmentation -psm qui prend les modes de segmentation suivants :
- 0 Détection de l’orientation et du script (OSD) uniquement.
- 1 Segmentation de page automatique avec OSD.
- 2 Segmentation de page automatique, mais sans OSD ni OCR. (non implémenté)
- 3 Segmentation de page entièrement automatique, mais sans OSD. (Par défaut)
- 4 Supposer une seule colonne de texte de tailles variables.
- 5 Supposer un seul bloc uniforme de texte aligné verticalement.
- 6 Supposer un seul bloc uniforme de texte.
- 7 Traiter l’image comme une seule ligne de texte.
- 8 Traiter l’image comme un seul mot.
- 9 Traiter l’image comme un seul mot dans un cercle.
- 10 Traiter l’image comme un seul caractère.
- 11 Texte clairsemé. Trouver autant de texte que possible sans ordre particulier.
- 12 Texte clairsemé avec OSD.
- 13 Ligne brute. Traiter l’image comme une seule ligne de texte, en contournant les astuces spécifiques à Tesseract.
tesseract <chemin_vers_l_image> --psm 12Quels sont les moteurs de reconnaissance optique de caractères ?
En passant le flag --oem et un nombre à Tesseract, vous pouvez choisir quel moteur OCR choisir.
Vous pouvez passer à Tesseract le nombre :
- 0 est pour utiliser le moteur legacy seulement
- 1 est pour utiliser le moteur de reseau neuronal LSTM seulement
- 2 est pour utiliser le moteur legacy et les moteurs LSTM
- 3 est l’option par défaut, Tesseract va prendre ce qu’il trouve
Pour vous retrouver avec une commande comme ceci :
tesseract <chemin_vers_l_image> --oem 1Les options de lecture image_to_string en Python avec PyTesseract
Avec PyTesseract, on peut aussi utiliser ces options dans la fonction presserait.image_to_string avec le paramètre optionnel config.
import pytesseract
mon_texte = pytesseract.image_to_string(image, config="--psm 4")Formation recommandée
250+ Exercices pour Apprendre Python
Apprenez Python efficacement avec plus de 250 exercices pratiques progressifs.



Je m'appelle Thomas, et je code depuis plus de 20 ans. Depuis ma sortie de la première promotion de l'École 42, j'ai conçu et développé des centaines d'applications et de sites web. Sur ce blog, je partage avec vous les stratégies les plus efficaces pour maîtriser l'art de coder et progresser rapidement.